AWS Glue Job - Pourquoi & comment tester en local ?
Ce guide pratique explique comment tester localement les jobs AWS Glue, un service serverless d'intégration de données. L'article souligne l'importance du test local pour accélérer le développement, réduire les coûts et faciliter le débogage. Il détaille ensuite une méthode en trois étapes pour configurer un environnement de test local. Ce tutoriel vise à optimiser le processus de développement des jobs AWS Glue, permettant aux data engineers de tester efficacement leur code avant le déploiement en production.

AWS Glue est un service serverless phare d’AWS pour l’intégration de données. Pour les data engineers spécialisés en big data, sa magie réside principalement dans le fait qu’il nous permet de nous concentrer entièrement sur Spark et son optimisation, tout en déléguant à AWS la gestion de l'infrastructure avec un paramétrage minimal pour commencer. Bien sûr, il est possible de peaufiner la configuration pour les jobs les plus complexes.
I - Pourquoi tester en local ?
Le serverless, bien qu'extrêmement pratique pour le calcul distribué, peut également rendre la phase d'implémentation et de test complexe. Chaque modification implique de lancer le job, d'attendre que le cluster soit prêt, et de découvrir parfois que le job échoue dès le début à cause d'une policy IAM manquante, d'une erreur sur les colonnes d'un DataFrame, ou d'autres problèmes similaires.
Qui a déjà réussi à lancer ses scripts dès le début sans aucun bug ? Si vous avez le secret, faites-le-moi savoir, je suis très intéressé !
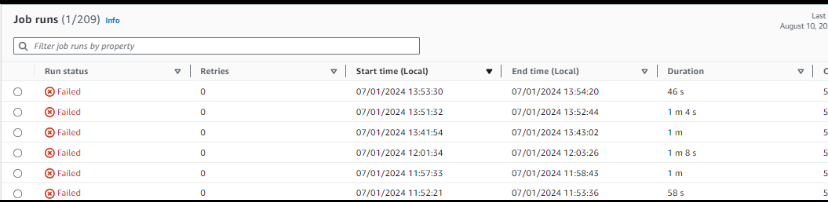
Le coût de l’itération de développement est élevé :
- 5 à 15 minutes perdues pour déployer le script Glue et lancer le job.
- Coût des DPU pour toutes les minutes où le cluster a tourné avant d’échouer.
- Temps de débogage sans possibilité de déboguer directement l’environnement Glue.
- Pour le sessions interactives, Grosse économie de DPU pendant les devs.
Tester en local devient alors une nécessité pour accélérer le développement et réduire les coûts en ressources humaines et matérielles.
En bonus, cela permet d’implémenter des tests unitaires, une pratique essentielle pour un développement serein.
II - Comment tester en local ?
Pour réussir à tester en local, voici les trois étapes principales :
- Puller l’image Docker Glue à la version qui vous intéresse (à ce jour, la version 4.0).
- Lancer et attacher le conteneur à votre IDE (Pycharm). Pour Visual Studio Code, voir la documentation existante sur mon github.
- Option bonus : L’attacher à un notebook pour une exploration plus interactive des données.
- Lancer le débogage, les tests unitaires, ou utiliser le notebook pour découvrir la donnée et tester pas à pas.
1 - Puller l’image Glue sur Docker
Pour Glue version 2.0, 3.0 ou 4.0, utilisez la commande suivante dans le terminal :
Docker Pull amazon/aws-glue-libs:glue_libs_{glue_version}.0.0_image_01
2 - Configurer Pycharm et attacher l’image
Dans cette section, nous allons voir comment exécuter notre code dans l’IDE (Pycharm) pour qu’il se lance avec l’environnement Glue de l’image Docker.
Une fois votre projet pyspark ouvert. ( et si vous n’en avez pas, vous pouvez simplement créer un projet et rajouter ce fichier glue_script.py qu’on pourra tester tout à l’heure. )
A - Configurer l’interpréteur Python :
- Ouvrez votre projet PySpark dans Pycharm. (Si vous n’avez pas de projet, vous pouvez en créer un et ajouter un fichier glue_script.py pour tester.)
- Configurer l’interpréteur Python :
- Allez dans File > Settings et recherchez "Python Interpreter". Cliquez sur Add Interpreter et bien sélectionner - on Docker -
- Choisissez Docker et Pull or use existing et dans image tag utilisez l’image téléchargée plus haut (amazon/aws-glue_libs:glue_libs_4.0.0.0_image_01).
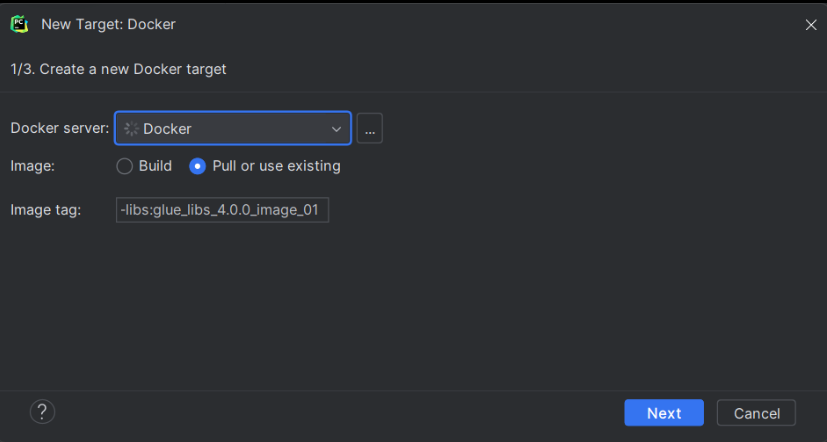
- Dans l'étape 3 : Assurez-vous que l’interpréteur Python détecté est /usr/local/bin/python3.
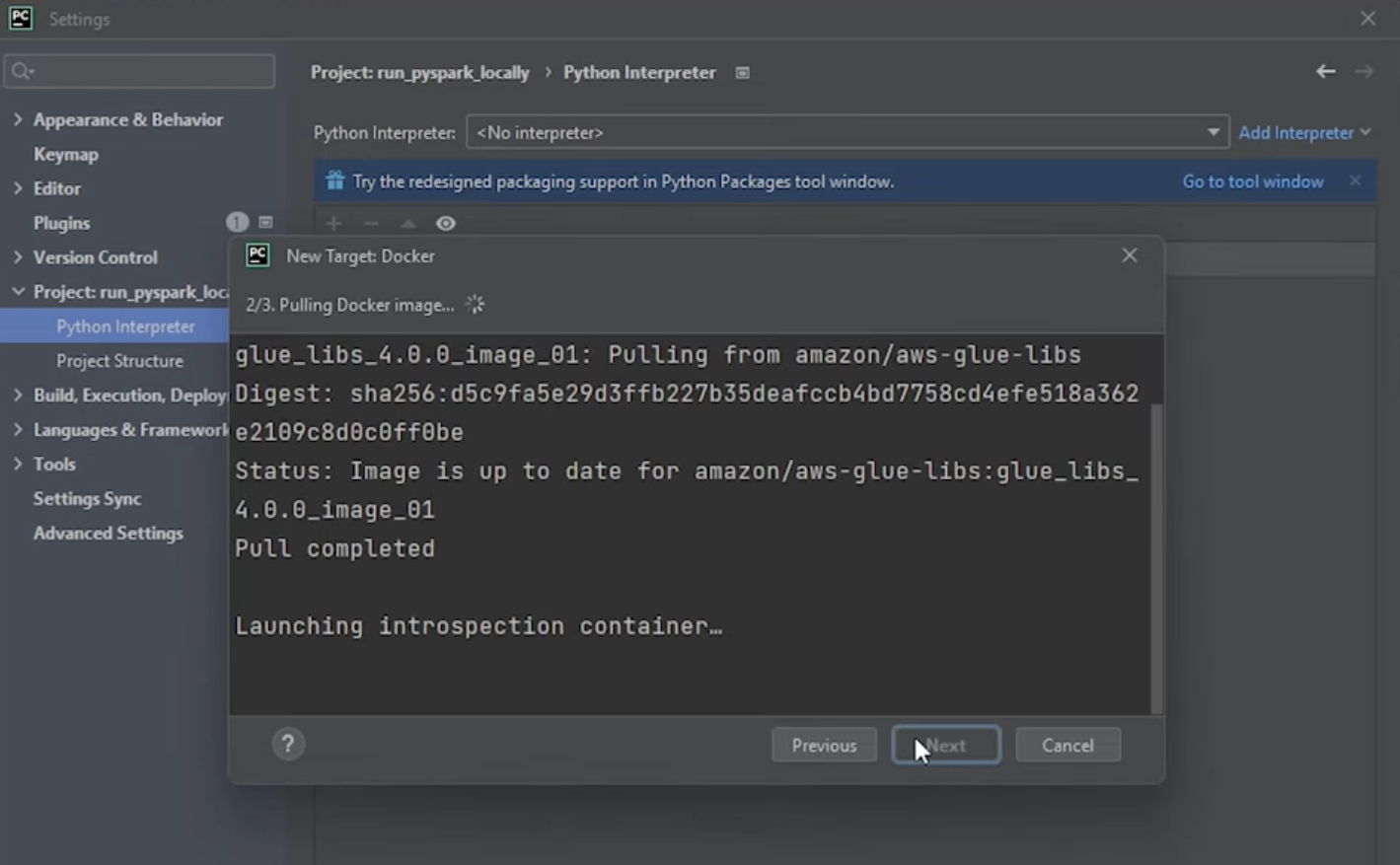
- Cliquez sur Create.
B - Edit configuration script
Dans la conf, nous allons principalement modifier les variables d’environnement ainsi que docker container settings.
1 - Python Path :
Maintenant qu’on a configuré l’interpréteur, il faut faire attention à bien spécifier à pycharm où est-ce qu’il va trouver les fichiers sources python utilisés dans le conteneur Docker.
On devra ajouter une variable d’environnement PYTHONPATH
Pour glue 4.0, on devra la compléter avec
/home/glue_user/aws-glue-libs/PyGlue.zip:/home/glue_user/spark/python/lib/py4j-0.10.9-src.zip:/home/glue_user/spark/python/
Pour les autres versions, il faut aller voir le build docker de l’image
https://hub.docker.com/r/amazon/aws-glue-libs/tags
Choisir la version qui nous intéresse et récupérer la variable Python Path comme ci-dessous.
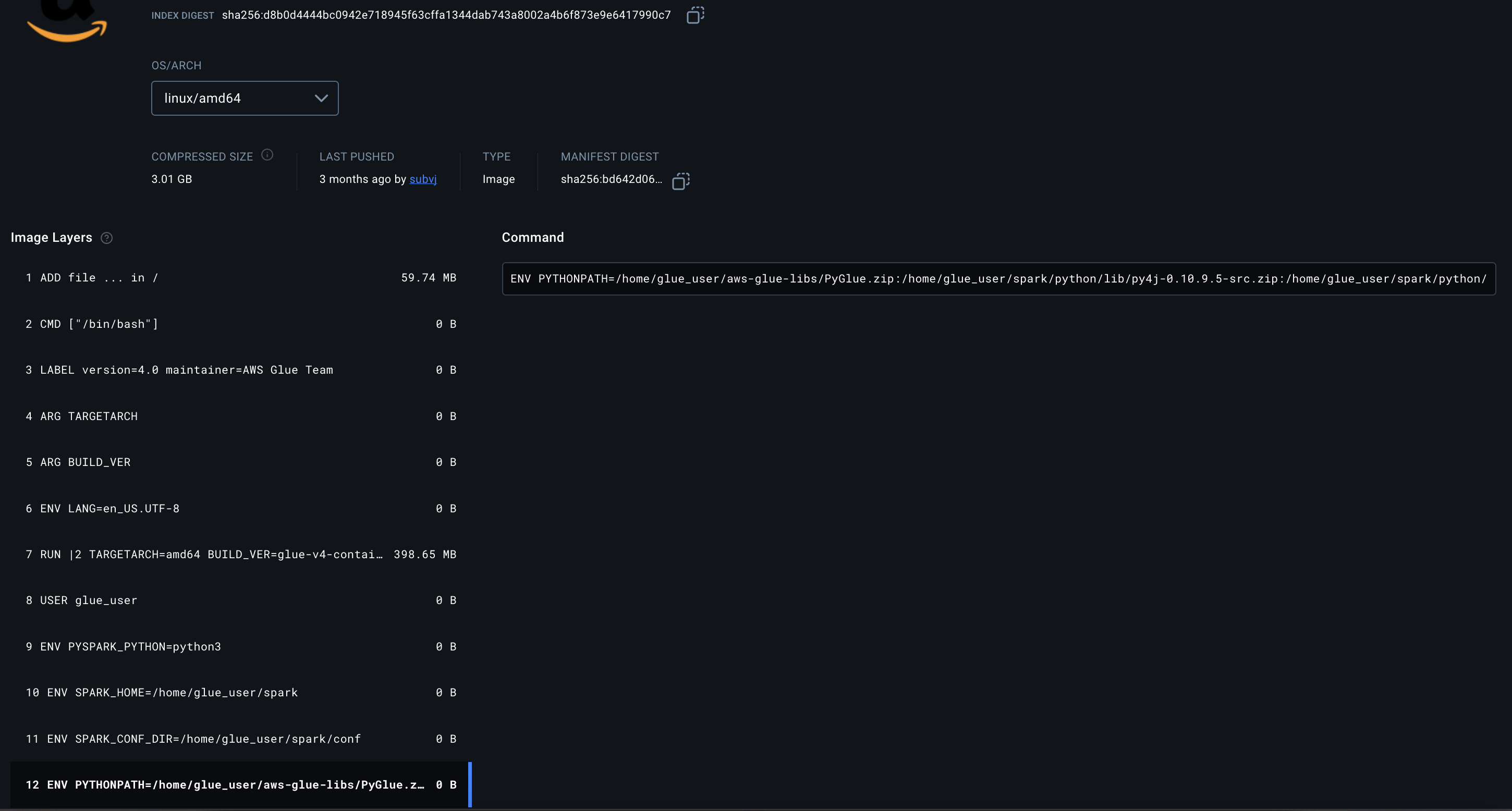
2 - Docker Container Settings :
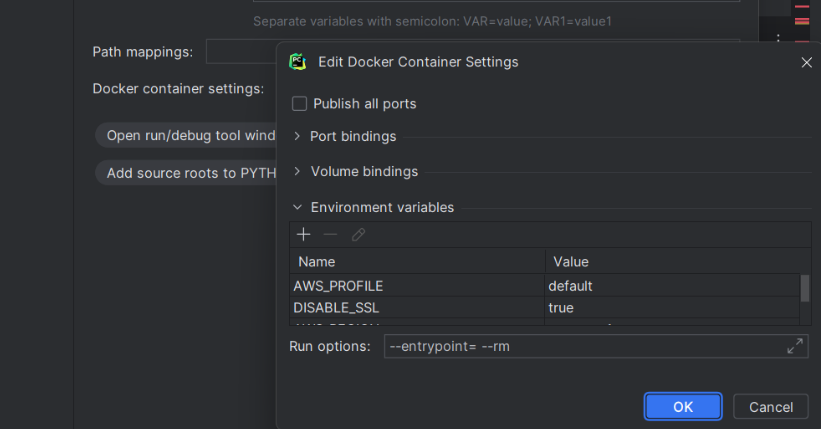
Concrètement c’est là où on va faire la configuration de run du Docker.
Les fameux paramètre -v ou -p par ex. lorsqu’on fait un Docker Run sur terminal.
Petit rappel :
v pour volume mounting, p port binding par ex: -v local_path:docker_path -p 8080:80 etc.
Ici pour l’intégration avec AWS, il ne faudra pas oublier d’inclure les Credentials AWS dans Volume bindings.
- Volume bindings : Host path: ~/.aws, Container path: /root/.aws
N’oublions pas de rajouter les variables d’environnement dans le AWS_PROFILE et AWS_REGION avec vos paramètres.
C - Lancer le script & have fun =)
À partir de là, vous pouvez lancer le script ou le déboguer exactement comme un script normal dans Pycharm. L’exécution sera légèrement plus longue car le conteneur doit se lancer et charger Spark avant que le code ne s’exécute, mais cela ne prend que quelques secondes, bien moins que de devoir déployer le code sur Glue et tester directement sur le job.
Bonus:
Les modules et objets Glue de votre projet ou script peuvent ne pas être reconnus et être soulignés en rouge dans Pycharm. Cela est dû au fait que Pycharm ne les reconnaît pas, car votre interpréteur Python est dans l’image Docker.
Une astuce simple est de cloner le repo sur Github : https://github.com/awslabs/aws-glue-libs
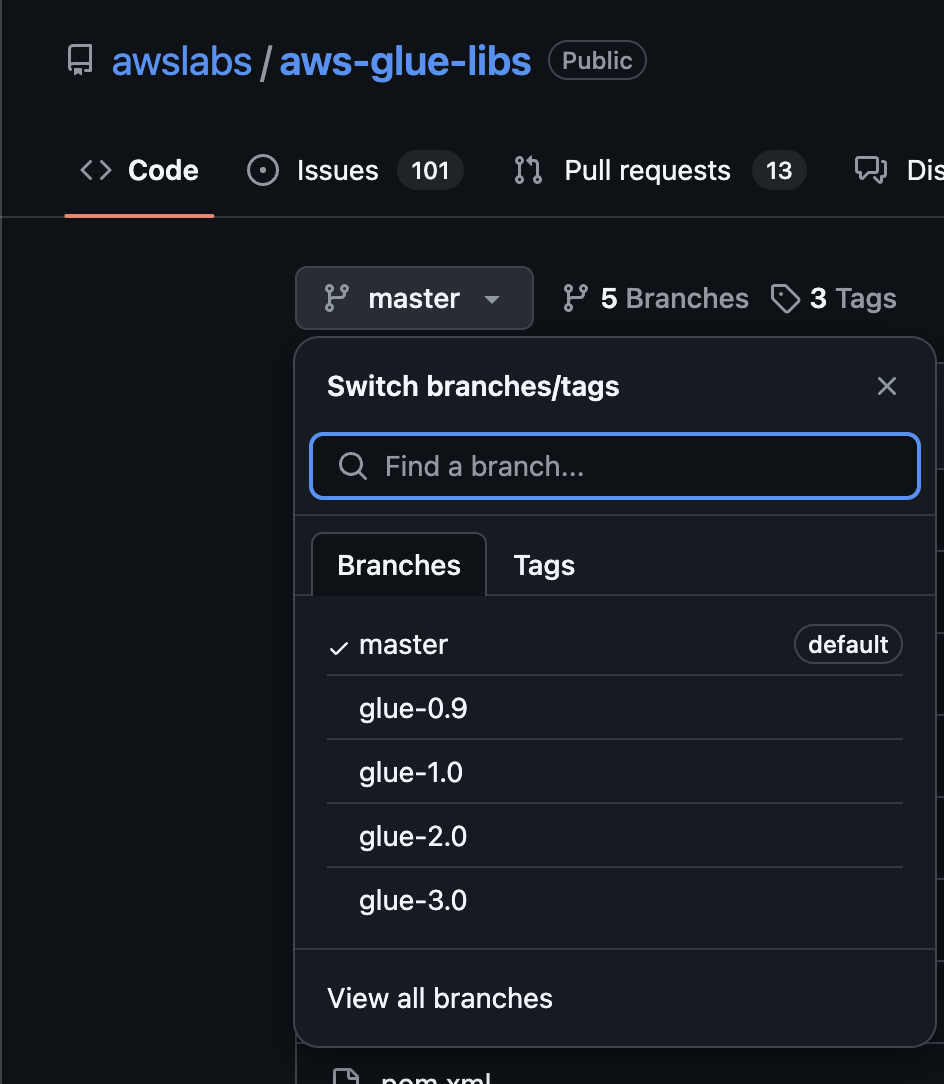
Clonez la branche qui vous intéresse. La branche master est pour la dernière version GLUE dispo. Ici c’est la 4.0.
git clone -b master https://github.com/awslabs/aws-glue-libs.git
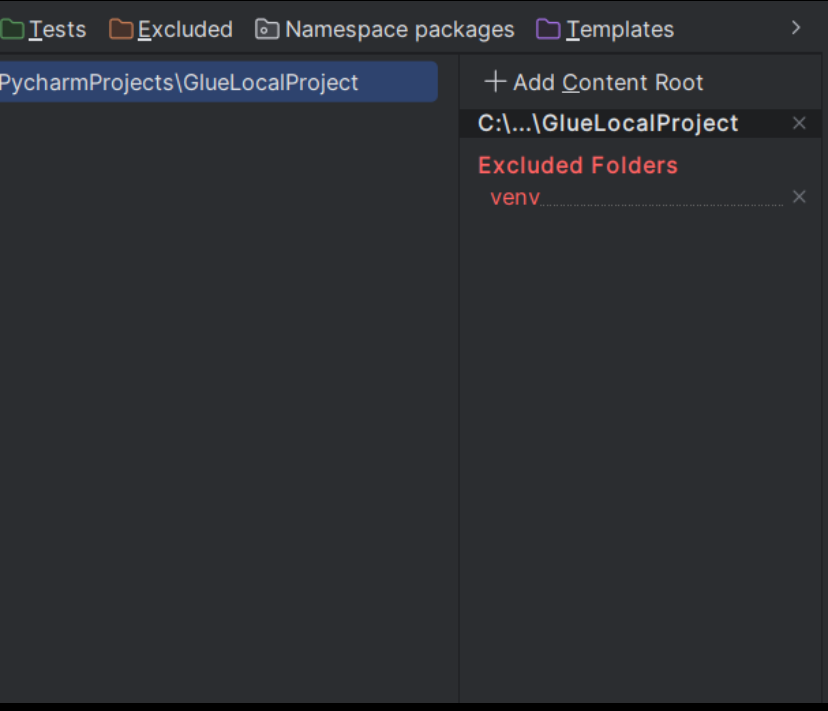
Ensuite, dans Pycharm, allez dans File > Settings > Project Structure > Add Content Roots et ajoutez le chemin local où vous avez cloné aws-glue-libs.
Conclusion
Le cloud computing a révolutionné l’industrie tech, notamment celle de la data, en permettant de gérer de grandes quantités de stockage et de calcul sans avoir besoin de lourdes infrastructures physiques. Le calcul distribué est au cœur de ces architectures à grande échelle, mais il nécessite une expertise poussée pour être géré efficacement.
Le serverless, en ajoutant une couche d’abstraction, permet de se concentrer directement sur le côté fonctionnel sans le moindre overhead opérationnel. Il y a bien des serveurs derrière, mais vous n’avez pas besoin de les gérer ou de les administrer. Vous pouvez vous concentrer à 100 % sur la fonctionnalité.
Tester vos jobs AWS Glue en local vous permet de gagner du temps et de l'argent tout en vous assurant que votre code est prêt pour la production, réduisant ainsi les risques de bugs après déploiement.











